引言
本人正有学习嵌入式的想法,正好碰到机会让我搞了块OrangePi AIpro(香橙派AIpro)开发板,正合我意,直接上手进行体验,顺便给大家分享下我的实践过程。
开发板介绍与初次启动
OrangePiAIPro开发板是香橙派联合华为精心打造的高性能AI开发板,其搭载了异腾AI处理器,可提供8TOPS INT8的计算能力,内存提供了8GB和16GB两种版本。可以实现图像、视频等多种数据分析与推理计算,可广泛用于教育、机器人、无人机等场景。

(这张是我自己拍的实体图)
资源介绍
开发板具有丰富的外设资源,详细情况如下表所示:
| 异腾AI处理器 | 4核64位Arm处理器+AI处理器 |
|---|---|
| AI算力 | 半精度(FP16): 4TFL0PS 整数精度(INT8) :8 T0PS |
| 内存 | 类型: LPDDR4X 容量: 8GB或16GB |
| 储存 | 板载32MB的SPI Flash Micro SD卡插槽 eMMC 插座:可外接eMMC模块 M.2 M-Key接口:可接2280规格的NVMe SSD 或SATA SSD |
| 以太网 | 支持10/100/ 1000Mbps 板载PHY芯片: RTL8211F |
| WiFi+蓝牙 | 支持2.4G和5G双频WIFI BT4.2 模组:欧智通6221BUUC |
| USB接口 | 2个USB3.0 Host接口 1个Type-C接口(注:只支持USB3.0,不支持USB2.0) |
| 摄像头 | 2个MIPICSI2Lane接口 |
| 显示接口 | 2个HDMI接口 1个MIPIDSI2Lane接口 |
| 音频接口 | 1个3.5mm耳机孔,支持音频输入输出 2个HDMI音频输出 |
| 40 pin扩展口 | 用于扩展UART、I2C、 SPI、 PWM和GPI0等接口 |
| 其他硬件接口 | 4pin 风扇接口,用于接12V风扇,支持PWM调节 2pin 电池接口,用于接3串电池,支持快充 Micro USB串口调试接口 1个MIPIDSI2Lane接口 |
开发板资源位置说明如下图

注:关机键只能用于强制关机,但是不能用于开机;而RESET键既可以用于开机也可以用于开发板重启。

镜像介绍与烧入
开发板支持的操作系统有:ubuntu 22.04与openEuler 22.03,👉点击即可下载镜像。
开发板支持多种镜像烧入方式:烧写Linux镜像到TF卡中、烧写 Linux 镜像到NVMe SSD中、烧写 Linux 镜像到 eMMC 中三中方式,由于在一般情况下使用方法一更多,因此在本文中就只介绍使用方法一烧写Linux镜像到TF卡中:
- 准备一张 32GB 或更大容量的 TF 卡(推荐使用 64GB 或以上容量的 TF 卡),并准备一个读卡器。
- 从官网Orange Pi - Orangepi下载 Linux 镜像与烧入软件balenaEtcher压缩包。
- 烧录镜像:将TF卡插入读卡器并连接到电脑。打开balenaEtcher,选择下载的Linux镜像文件和TF卡,然后点击"Flash"开始烧录。
- 烧录完成后,将TF卡插入香橙派Alpro的TF卡槽即可。
这些东西我就不详细介绍了,不懂的朋友可以参考下这篇:https://www.hiascend.com/forum/thread-0260140249549075069-1-1.html
串口调试
开发板默认使用uart0做为调试串口,但是需要注意的是,uart0的tx和rx引脚同时接到了两个地方,因此有两种使用调试串口的方法:
1.借助USB转TTL模块完成串口数据传输
uart0的tx和rx引脚接到了40 pin扩展接口中的8号和10号引脚,此种方式需要准备一个3.3v的USB转TTL模块和相应的杜邦线,然后才能正常使用开发板的调试串口功能。开发板上预留的串口接口如下图所示:
2.借助Micro USB接口的数据线完成串口数据传输
uart0的tx和rx引脚又接到了开发板的CH343P芯片上,再通过CH343P芯片引出到MicroUSB接口.上。此种方式只需要一根MicroUSB接口的数据线将开发板连接到电脑的USB接口就可以开始使用开发板的调试串口功能了,无需购买USB转TTL模块。这种方法是推荐的方法。
启动开发板
- 将烧录好镜像的TF卡或者eMMC模块或者SSD插入开发板对应的插槽中。
- 连接电源,板子会自己启动。
开发板正常启动后:

连接开发板
首先得让开发连上网络,咱给他插上网线,然后到路由器的管理系统里去找到那个插网线的设备ip地址。

接下来我们就可以通过这个ip来连接设备了,我使用的是finalShell,个人比较习惯一点。
默认账号是 HwHiAiUser,密码默认是 Mind@123,然后就可以连上开发板了。
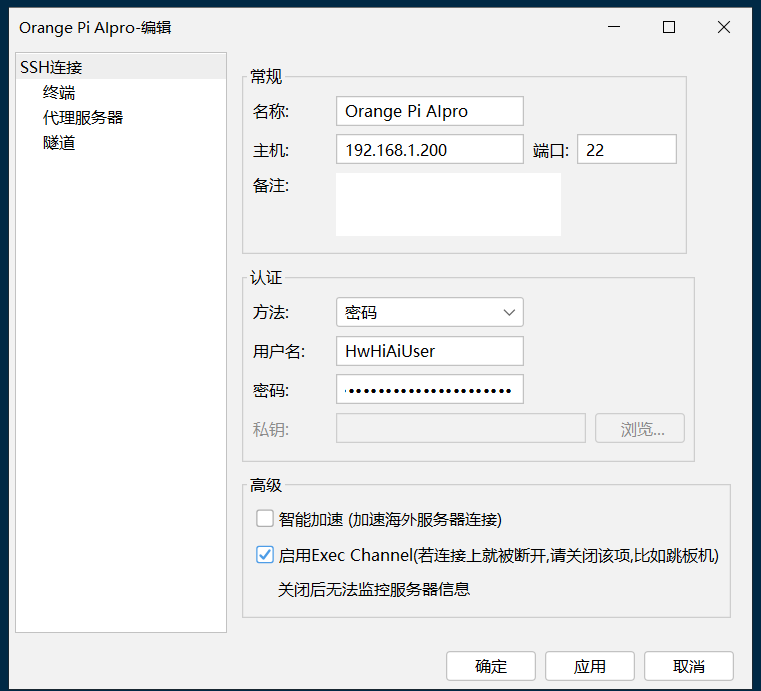
登录成功:
接下来我们弄个项目来体验下这块 OrangePi AIpro 开发板。
车牌识别系统
基于Opencv的车牌识别系统
这个程序是参考博客【OpenCV实战】简洁易懂的车牌号识别Python+OpenCV实现“超详解”(含代码),然后手动创建的项目代码。
首先给出我们要识别的目标原图(注:图片来源于网上)

车牌定位是车牌识别过程中的关键步骤,它旨在从图像中准确地找到车牌的位置,定位结果通常以车牌区域的最小外接矩形形式给出,该矩形精确地标记了车牌在图像中的位置。以下是一些关键的步骤和方法:
- 颜色空间转换
- HSV颜色空间:由于车牌颜色(如蓝色、黄色等)在HSV颜色空间中具有较高的饱和度,因此可以将图像从RGB颜色空间转换到HSV颜色空间,然后基于颜色阈值来检测车牌区域。
- 阈值处理:根据车牌颜色的HSV值范围设置阈值,将图像二值化,突出车牌区域。
- 形态学操作
- 腐蚀与膨胀:使用形态学操作中的腐蚀和膨胀操作来去除噪声和填补车牌区域中的小洞。
- 开运算与闭运算:结合腐蚀和膨胀操作,形成开运算和闭运算,进一步清理车牌区域边界。
- 轮廓检测
- findContours函数:使用OpenCV中的findContours函数检测图像中的轮廓。
- 轮廓筛选:根据轮廓的面积、长宽比、形状等特征筛选出车牌轮廓。
- 车牌区域提取
- 最小外接矩形:对于筛选出的车牌轮廓,使用最小外接矩形来标记车牌区域。
- 裁剪:从原图中裁剪出车牌区域,用于后续的字符分割和识别。
代码实现如下:
# 读取图像
origin_image = cv2.imread('car.jpg')
if origin_image is None:
print("Error: Image not found.")
return
# 图像预处理
gray_image = preprocess_image(origin_image)
# 边缘检测
sobel_x = cv2.Sobel(gray_image, cv2.CV_16S, 1, 0)
abs_sobel_x = cv2.convertScaleAbs(sobel_x)
# 阈值化
_, binary_image = cv2.threshold(abs_sobel_x, 0, 255, cv2.THRESH_OTSU)
# 形态学操作
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (30, 10))
binary_image = cv2.morphologyEx(binary_image, cv2.MORPH_CLOSE, kernel, iterations=1)
# 腐蚀和膨胀
kernel_x = cv2.getStructuringElement(cv2.MORPH_RECT, (50, 1))
kernel_y = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 20))
binary_image = cv2.dilate(binary_image, kernel_x)
binary_image = cv2.erode(binary_image, kernel_x)
binary_image = cv2.erode(binary_image, kernel_y)
binary_image = cv2.dilate(binary_image, kernel_y)
binary_image = cv2.medianBlur(binary_image, 21)
# 轮廓检测
contours, _ = cv2.findContours(binary_image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
rect = cv2.boundingRect(contour)
x, y, width, height = rect
if width > height * 3 and width <= height * 4:
plate_image = origin_image[y:y + height, x:x + width]
plt_show_color(plate_image)
break # 假设只处理一个车牌
输出的过程图片如下:

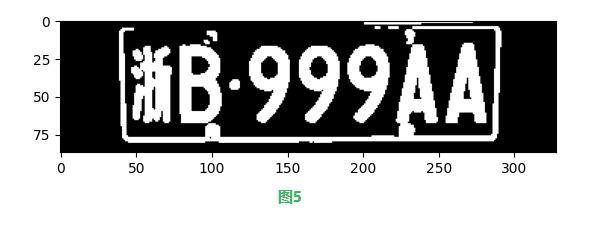
字符分割是将车牌区域中的字符逐一分离出来的过程,为后续的字符识别做准备。以下是一些常用的方法:
- 投影法
- 水平投影:对车牌区域进行水平方向的投影,统计每行的像素和,找到字符之间的分隔线。
- 垂直投影:类似地,也可以进行垂直方向的投影,但通常用于后续字符的微调。
- 连通区域分析
- 标记连通组件:使用连通区域分析算法(如标签连通组件)来标记车牌区域中的每个字符。
- 分割:根据连通组件的边界分割出每个字符。
- 字符归一化
- 大小调整:将所有分割出的字符调整到统一的大小,以便于后续的字符识别。
- 位置校正:对字符进行必要的旋转或倾斜校正,以提高识别准确率。
代码实现如下:
# 字符分割和模板匹配
gray_plate = preprocess_image(plate_image)
_, binary_plate = cv2.threshold(gray_plate, 0, 255, cv2.THRESH_OTSU)
binary_plate = cv2.dilate(binary_plate, cv2.getStructuringElement(cv2.MORPH_RECT, (2, 2)))
contours, _ = cv2.findContours(binary_plate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
words = sorted(contours, key=lambda x: cv2.boundingRect(x)[0])
word_images = []
for contour in words:
rect = cv2.boundingRect(contour)
x, y, width, height = rect
if height > width * 1.5 and height < width * 3.5 and width > 25:
word_img = binary_plate[y:y + height, x:x + width]
word_images.append(word_img)
# 显示分割后的字符
for i, img in enumerate(word_images):
plt.subplot(1, len(word_images), i + 1)
plt.imshow(img, cmap='gray')
plt.show()
过程结果如下:
字符识别是车牌识别过程中的最后一步,目的是将分割出的字符图像转换为对应的文本信息。以下是一些常用的方法:
- 特征提取
- 传统特征:如HOG(方向梯度直方图)、LBP(局部二值模式)等特征提取方法。
- 深度学习特征:使用卷积神经网络(CNN)等深度学习模型自动提取字符图像的特征。
- 分类器训练
- 传统分类器:如SVM(支持向量机)、KNN(K最近邻)等分类器。
- 深度学习模型:如CNN、RNN(循环神经网络)等深度学习模型,特别是针对字符识别优化的网络结构。
- 模型评估
- 测试集评估:使用独立的测试集来评估模型的性能,包括准确率、召回率等指标。
- 交叉验证:采用交叉验证方法来提高模型的泛化能力。
代码实现如下:
# 对分割得到的字符逐一匹配
def template_matching(word_images):
results = []
for index, word_image in enumerate(word_images):
if index == 0:
best_score = []
for chinese_words in chinese_words_list:
score = []
for chinese_word in chinese_words:
result = template_score(chinese_word, word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[34+i])
r = template[34 + i]
results.append(r)
continue
if index == 1:
best_score = []
for eng_word_list in eng_words_list:
score = []
for eng_word in eng_word_list:
result = template_score(eng_word, word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[10+i])
r = template[10 + i]
results.append(r)
continue
else:
best_score = []
for eng_num_word_list in eng_num_words_list:
score = []
for eng_num_word in eng_num_word_list:
result = template_score(eng_num_word, word_image)
score.append(result)
best_score.append(max(score))
i = best_score.index(max(best_score))
# print(template[i])
r = template[i]
results.append(r)
continue
return results
word_images_ = word_images.copy()
# 调用函数获得结果
result = template_matching(word_images_)
print(result)
# "".join(result)函数将列表转换为拼接好的字符串,方便结果显示
print("".join(result))
代码搞定之后,我们把代码上传到 OrangePi AIpro 上,然后安装下Python环境什么的,直接运行就好了,这步比较简单,就不多说了。
最终识别出来的结果如下:
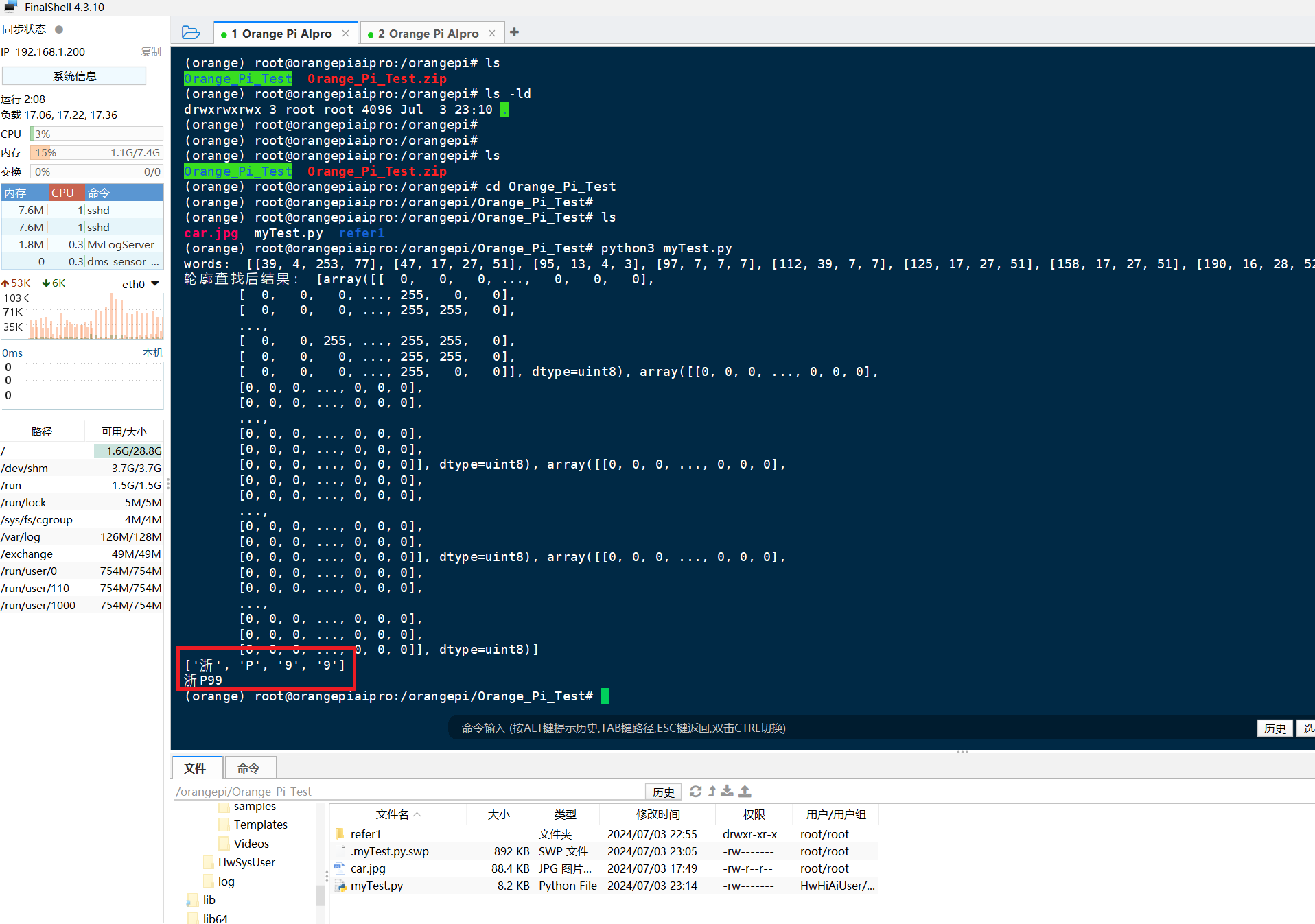
由于我这里给的数据集比较少,所以识别的不太准确,但也识别出了个大概(也可能是我代码写太烂了,玩的就是一个真实😅)。
所以我又找了基于Yolov5的车牌识别,想要识别出更加准确的结果。
基于Yolov5的车牌识别系统
首先给出项目的开源地址:Chinese_license_plate_detection_recognition,该项目是一个基于深度学习与yolov5 的车牌检测 、车牌识别、中文车牌识别与检测、支持12种中文车牌、支持双层车牌的目标识别系统。
相关知识介绍
深度学习(Deep Learning, DL)是机器学习(Machine Learning, ML)领域中一个重要的研究方向,旨在通过构建多层人工神经网络(Artificial Neural Networks, ANNs)来模拟人脑的学习过程,从而实现对复杂数据的自动分析和理解。深度学习具有多层结构、自动特征提取、非线性建模、大规模数据处理的能力,目前广泛应用于计算机视觉、自然语言处理、语音识别等领域。
YOLOv5(You Only Look Once version 5)是YOLO系列算法的最新版本之一,其具备高速和高精度的特点,在实时目标检测任务中表现出色。它继承了YOLO系列算法的核心思想,即将目标检测任务视为一个回归问题,通过卷积神经网络直接预测目标的边界框和类别概率。其网络结构可以分为三个部分:Backbone(主干网络)、Neck(颈部网络)和Head(头部网络),适用于多种实时目标监测场景,如:视频监控、自动驾驶、工业检测等。
项目拉取步骤
使用git命令拉取项目
git clone https://github.com/we0091234/Chinese_license_plate_detection_recognition.git

拉取完成后,需要下载相关依赖,大家可直接使用下面的下载命令
pip install -r ./requirements.txt -i https://mirrors.aliyun.com/pypi/simple
由于项目所需要依赖过多,下载时间会稍微有一点长,这里建议大家在下载过程中可以伸个懒腰休息一下,O(∩_∩)O哈哈~。(如果在下载过程中遇到问题,可以到后面的报错解决方法中看看)
模型训练
该项目中各种路径都已配置完成,当我们需要训练自己的模型时只需要更改data/widerface.yaml文件中的train与val路径即可。
train: /mnt/Gpan/Mydata/pytorchPorject/yolov5-face/ccpd/train_detect
val: /mnt/Gpan/Mydata/pytorchPorject/yolov5-face/ccpd/val_detect
更改说明
train: /your/train/path #修改成你的训练集路径
val: /your/val/path #修改成你的验证集路径
更改完成后可直接使用命令开始训练
python3 train.py --data data/widerface.yaml --cfg models/yolov5n-0.5.yaml --weights weights/plate_detect.pt --epoch 120
命令解析
- python3 train.py:使用Python 3解释器来运行名为train.py的脚本文件。这个脚本很可能是YOLOv5框架中用于训练模型的脚本。
- –data data/widerface.yaml:这个参数指定了训练数据集的配置文件路径。widerface.yaml文件应该包含了训练所需的数据集路径、类别信息、增强策略等配置信息。
- –cfg models/yolov5n-0.5.yaml:这个参数指定了模型配置文件的路径。yolov5n-0.5.yaml文件定义了YOLOv5模型的结构,包括网络的层数、参数、锚点(anchors)等配置。
- –weights weights/plate_detect.pt:这个参数指定了预训练权重的路径。这表示训练过程将从plate_detect.pt这个预训练的车牌检测模型开始,而不是从头开始训练。这有助于加速训练过程,并可能提高最终模型的性能。
- –epoch 120:这个参数指定了训练的轮次(epoch)数。这意味着整个训练数据集将被遍历120次,以进行模型的学习和优化。
最终训练的结果都保存在run文件夹中。
关键函数介绍
识别车牌,包括车牌的边界框、四个角点坐标、车牌号以及(可选地)车牌颜色。下面是该函数的详细实现步骤:函数的主要逻辑如下:
- 初始化参数:
- 从输入图像img获取其高度h、宽度w和通道数c。
- 初始化一个空字典result_dict用于存储结果。
- 计算线条/字体粗细tl,这里基于图像尺寸动态计算。
- 解析车牌位置和角点坐标:
- 从xyxy(车牌边界框的坐标,格式为[x1, y1, x2, y2])中提取车牌的左上角和右下角坐标。
- 初始化一个NumPy数组landmarks_np用于存储车牌的四个角点坐标。
- 遍历landmarks(车牌角点坐标列表),将每个角点坐标(x, y)存入landmarks_np。
- 获取车牌类型:
- 从class_num获取车牌类型(0代表单牌,1代表双层车牌)。
- 透视变换获取车牌小图:
- 使用four_point_transform函数(需要预先定义或导入)对车牌区域进行透视变换,得到车牌的正面视图roi_img。
- 处理双层车牌:
- 如果车牌类型为双层(class_label为1),则调用get_split_merge函数(需要预先定义或导入)对车牌小图进行分割和合并处理。
- 车牌识别:
- 根据is_color参数决定是否需要识别车牌颜色。
- 调用get_plate_result函数(需要预先定义或导入)对车牌小图roi_img进行识别,获取车牌号plate_number、识别概率rec_prob,以及(如果is_color为True)车牌颜色plate_color和颜色置信度color_conf。
- 构建结果字典:
- 将车牌的边界框rect、检测置信度conf、角点坐标landmarks、车牌号plate_number、识别概率rec_prob、车牌高度roi_img.shape[0]、车牌颜色(如果is_color为True)以及车牌类型class_label等信息存入result_dict。
- 返回结果:
- 返回包含车牌识别结果的字典result_dict。
注意:
- four_point_transform和get_split_merge函数需要用户根据具体需求实现或导入相应的库。
- get_plate_result函数同样需要用户根据车牌识别模型的实际情况进行实现或调用已有的识别库。
- 在实际应用中,可能还需要对输入参数进行验证,以确保函数的健壮性。
代码实现如下所示
def get_plate_rec_landmark(img, xyxy, conf, landmarks, class_num,device,plate_rec_model,is_color=False): #获取车牌坐标以及四个角点坐标并获取车牌号
h,w,c = img.shape
result_dict={}
tl = 1 or round(0.002 * (h + w) / 2) + 1 # line/font thickness
x1 = int(xyxy[0])
y1 = int(xyxy[1])
x2 = int(xyxy[2])
y2 = int(xyxy[3])
height=y2-y1
landmarks_np=np.zeros((4,2))
rect=[x1,y1,x2,y2]
for i in range(4):
point_x = int(landmarks[2 * i])
point_y = int(landmarks[2 * i + 1])
landmarks_np[i]=np.array([point_x,point_y])
class_label= int(class_num) #车牌的的类型0代表单牌,1代表双层车牌
roi_img = four_point_transform(img,landmarks_np) #透视变换得到车牌小图
if class_label: #判断是否是双层车牌,是双牌的话进行分割后然后拼接
roi_img=get_split_merge(roi_img)
if not is_color:
plate_number,rec_prob = get_plate_result(roi_img,device,plate_rec_model,is_color=is_color) #对车牌小图进行识别
else:
plate_number,rec_prob,plate_color,color_conf=get_plate_result(roi_img,device,plate_rec_model,is_color=is_color)
# cv2.imwrite("roi.jpg",roi_img)
result_dict['rect']=rect #车牌roi区域
result_dict['detect_conf']=conf #检测区域得分
result_dict['landmarks']=landmarks_np.tolist() #车牌角点坐标
result_dict['plate_no']=plate_number #车牌号
result_dict['rec_conf']=rec_prob #每个字符的概率
result_dict['roi_height']=roi_img.shape[0] #车牌高度
result_dict['plate_color']=""
if is_color:
result_dict['plate_color']=plate_color #车牌颜色
result_dict['color_conf']=color_conf #颜色得分
result_dict['plate_type']=class_label #单双层 0单层 1双层
return result_dict
在给定的原始图片上绘制车牌识别的结果的函数流程:
-
初始化结果字符串:首先,创建一个空字符串result_str,用于拼接所有检测到的车牌号码,以便后续打印。
-
遍历检测结果:对于dict_list中的每一个结果(字典),执行以下操作:
a. 调整矩形区域:从结果字典中获取车牌的矩形区域rect_area(通常是一个包含四个整数的列表,表示矩形左上角的x、y坐标以及右下角的x、y坐标)。然后,根据车牌的宽度和高度,计算并调整矩形区域的大小,以确保车牌区域有适当的内边距,并且不会超出原始图片的边界。
b. 处理车牌类型和颜色:根据plate_type(车牌类型,0表示单层,非0表示双层)和plate_color(车牌颜色),构建车牌号码字符串result_p。对于双层车牌,会在车牌号码后附加“双层”字样。
c. 绘制关键点:如果结果中包含车牌的关键点(landmarks),则使用cv2.circle函数在原始图片上绘制这些点。颜色clors(注意这里可能是个笔误,通常应该是colors)应该是一个包含四种颜色的列表或元组,但由于在函数定义中没有提供colors,这里假设它是全局定义的。
d. 绘制车牌矩形框:使用cv2.rectangle函数在原始图片上绘制车牌的矩形框,颜色为红色。
e. 绘制车牌号码文本:首先,计算车牌号码文本的大小,以确保文本不会超出图片边界。然后,在车牌矩形框的上方绘制一个白色的背景框,用于突出显示车牌号码文本。最后,使用cv2ImgAddText(注意这个函数不是OpenCV的一部分,可能是自定义的)在白色背景框上绘制车牌号码文本,颜色为黑色。 -
打印结果字符串:在控制台打印出所有检测到的车牌号码字符串result_str。
-
返回处理后的图片:函数返回处理后的原始图片orgimg,该图片上已绘制了车牌的检测结果。
使用代码表达如下:
def draw_result(orgimg,dict_list,is_color=False): # 车牌结果画出来
result_str =""
for result in dict_list:
rect_area = result['rect']
x,y,w,h = rect_area[0],rect_area[1],rect_area[2]-rect_area[0],rect_area[3]-rect_area[1]
padding_w = 0.05*w
padding_h = 0.11*h
rect_area[0]=max(0,int(x-padding_w))
rect_area[1]=max(0,int(y-padding_h))
rect_area[2]=min(orgimg.shape[1],int(rect_area[2]+padding_w))
rect_area[3]=min(orgimg.shape[0],int(rect_area[3]+padding_h))
height_area = result['roi_height']
landmarks=result['landmarks']
result_p = result['plate_no']
if result['plate_type']==0:#单层
result_p+=" "+result['plate_color']
else: #双层
result_p+=" "+result['plate_color']+"双层"
result_str+=result_p+" "
for i in range(4): #关键点
cv2.circle(orgimg, (int(landmarks[i][0]), int(landmarks[i][1])), 5, clors[i], -1)
cv2.rectangle(orgimg,(rect_area[0],rect_area[1]),(rect_area[2],rect_area[3]),(0,0,255),2) #画框
labelSize = cv2.getTextSize(result_p,cv2.FONT_HERSHEY_SIMPLEX,0.5,1) #获得字体的大小
if rect_area[0]+labelSize[0][0]>orgimg.shape[1]: #防止显示的文字越界
rect_area[0]=int(orgimg.shape[1]-labelSize[0][0])
orgimg=cv2.rectangle(orgimg,(rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1]))),(int(rect_area[0]+round(1.2*labelSize[0][0])),rect_area[1]+labelSize[1]),(255,255,255),cv2.FILLED)#画文字框,背景白色
if len(result)>=1:
orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0],int(rect_area[1]-round(1.6*labelSize[0][1])),(0,0,0),21)
# orgimg=cv2ImgAddText(orgimg,result_p,rect_area[0]-height_area,rect_area[1]-height_area-10,(0,255,0),height_area)
print(result_str)
return orgimg
运行结果
在本次测试中,我直接了使用开源项目中的模型,开源项目中识别车牌的demo运行命令如下
python detect_plate.py --detect_model weights/plate_detect.pt --rec_model weights/plate_rec_color.pth --image_path imgs --output result
命令解析
- python detect_plate.py:这部分指示操作系统使用Python解释器来运行名为detect_plate.py的脚本文件。这是执行Python脚本的基本方式。
- –detect_model weights/plate_detect.pt:这是一个命令行参数,用于指定车牌检测模型的文件路径。–detect_model是参数名,用于告诉脚本应该使用哪个模型进行车牌检测;weights/plate_detect.pt是参数值,即模型文件的实际路径。这里的.pt文件很可能是PyTorch模型文件的扩展名,表明该模型可能是用PyTorch框架训练的。
- –rec_model weights/plate_rec_color.pth:与上一个参数类似,这个参数指定了车牌识别模型的文件路径。–rec_model是参数名,weights/plate_rec_color.pth是参数值。这里的.pth文件也是PyTorch模型文件的常见扩展名,表明该模型同样可能是用PyTorch框架训练的。
- –image_path imgs:这个参数指定了输入图像(或图像文件夹)的路径。
- –output result:这个参数指定了输出结果的存储位置。
在本次运行中,所有参与图片整合后如图 识别目标(由单个目标组合而成):

命令行结果
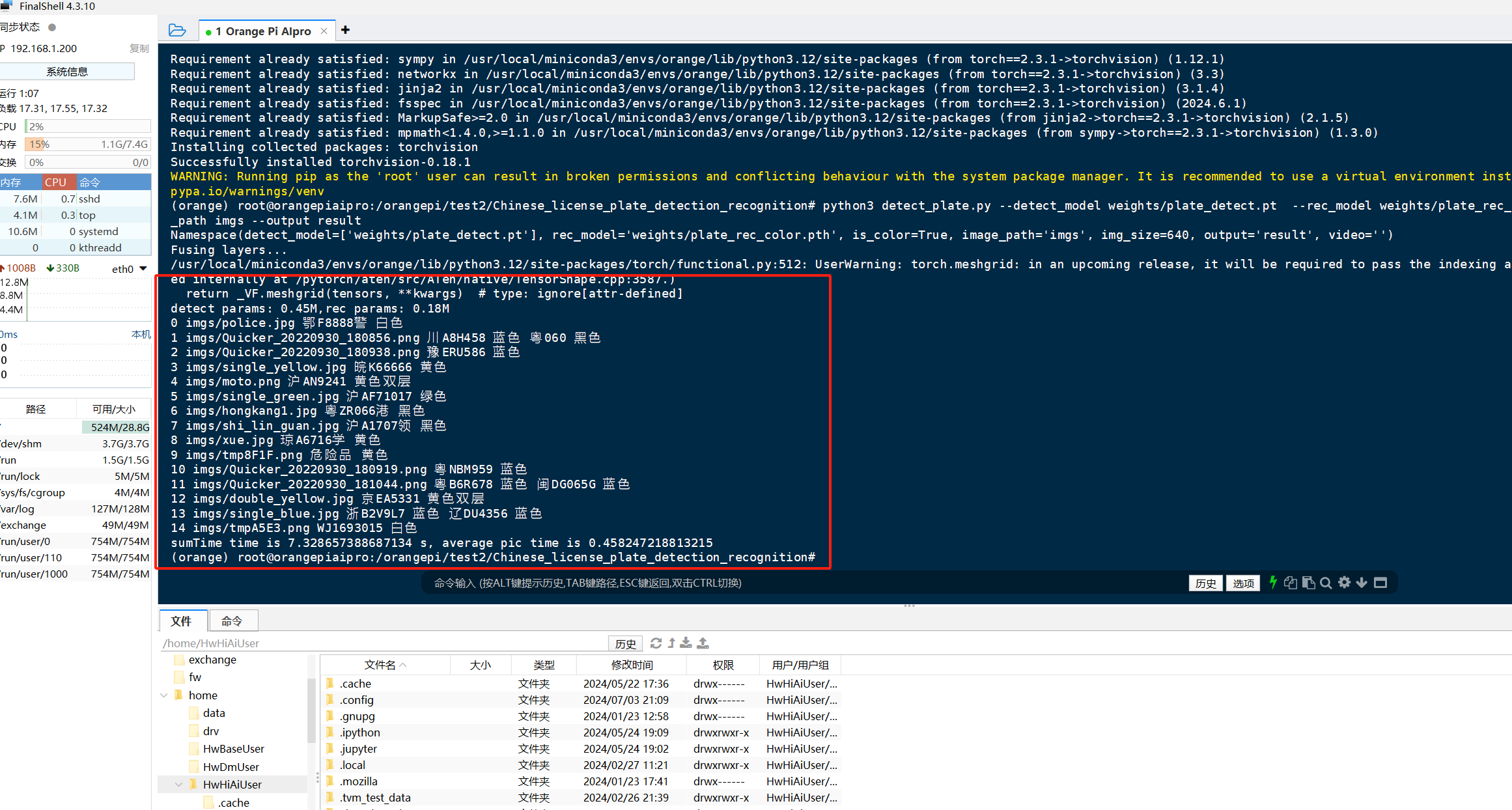
使用香橙派Aipro进行这组图片的识别,一共花了大约7.3 秒左右,平均每张0.45s左右,识别速度还是非常快的,可以做到秒级识别车牌号。
在本次运行中,所有结果图片整合后如图 识别目标结果(由单个目标结果组合而成):

运行过程中出现的报错与解决方法
报错1
Traceback (most recent call last):
File “openvino_infer.py”, line 4, in
from openvino.runtime import Core Module Not Found
Error: No module named ‘openvino’
解决方法:使用 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple openvino-dev下载工具包
报错2
Traceback (most recent call last):
File “detect_plate.py”, line 12, in
from models.experimental import attempt_load
File “/home/topeet/Desktop/Chinese_license_plate_detection_recognition/models/experimental.py”, line 7, in
from models.common import Conv, DWConv
File “/home/topeet/Desktop/Chinese_license_plate_detection_recognition/models/common.py”, line 11, in
from utils.datasets import letterbox
File “/home/topeet/Desktop/Chinese_license_plate_detection_recognition/utils/datasets.py”, line 23, in
from utils.general import xyxy2xywh, xywh2xyxy, xywhn2xyxy, clean_str
File “/home/topeet/Desktop/Chinese_license_plate_detection_recognition/utils/general.py”, line 16, in
import torchvision
ModuleNotFoundError: No module named ‘torchvision’
解决方法:pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple torchvision下载工具包
报错3
pip._vendor.urllib3.exceptions.ReadTimeoutError: HTTPSConnectionPool(host=‘pypi.tuna.tsinghua.edu.cn’, port=443): Read timed out.
这个问题一看就是网络不行超时了嘛,重新执行命令下载即可。
报错4
结果出现了杂项信息
Namespace(detect_model=[‘weights/plate_detect.pt’], image_path=‘imgs’, img_size=640, is_color=True, output=‘result’, rec_model=‘weights/plate_rec_color.pth’, video=‘’)
Fusing layers…
/home/topeet/.local/lib/python3.6/site-packages/torch/functional.py:445: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at …/aten/src/ATen/native/TensorShape.cpp:2157.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
解决方法:这是一个警告,自于 PyTorch 库,可能是在某个依赖库(如 torchvision 或其他你正在使用的深度学习库)中使用了 torch.meshgrid,并且没有指定 indexing 参数。
项目对比
就上面两个小项目而言,基于OpenCV的车牌识别系统依赖于边缘检测、形态学操作、模板匹配等图像处理技术,而基于YOLOv5的车牌识别系统则展现了显著的技术进步,采用端到端的深度神经网络架构,通过大规模数据训练自动学习车牌特征。
而YOLOv5作为先进的目标检测算法,其高效的特征提取能力在性能上表现为更快的处理速度和更高的识别准确率,单次前向传播即可直接输出目标类别与位置,简化了后处理流程。在复杂环境如光线变化、车牌污损、角度倾斜等挑战下,YOLOv5凭借其强大的特征提取能力,往往能提供更准确的车牌识别结果,相比之下,OpenCV系统在这些场景中的表现可能受限。此外,YOLOv5通过多尺度特征融合与跨层连接等技术,展现了对光照、遮挡、角度变化等复杂环境因素的强鲁棒性,而OpenCV系统虽具一定鲁棒性,但在极端或复杂条件下性能可能下降。
因此,无论是从技术先进性、处理性能、识别结果的准确性还是系统鲁棒性来看,基于深度学习与YOLOv5的车牌识别系统均全面超越了基于OpenCV的传统方法,预示着随着深度学习技术的持续发展,YOLOv5将在智能交通管理领域都会扮演愈发重要的角色。
使用体验与结论
体验
OrangePi AIpro 凭借其卓越的即插即用特性,极大地加速了开发进程。通过简单的配置步骤,我能够迅速将这款开发板无缝集成至我的开发环境中,省去了繁琐的硬件调试环节,从而节省了宝贵的研发时间。
在软件生态方面,香橙派社区构建了一个资源丰富、文档详尽的生态系统,这对初学者而言无疑是巨大的助力,让我能够轻松访问并选用适合的文字识别模型和框架,通过直观易懂的指南,快速部署至开发板上。此外,开发板还广泛兼容多种操作系统和编程环境,让我能根据个人偏好和项目需求灵活选择开发工具,进一步优化了开发流程,提高了工作效率。这边也贴一个OrangePi AIpro的学习资源一站式导航:https://www.hiascend.com/forum/thread-0285140173361311056-1-1.html。
结论
针对我做的这个项目,在实际应用场景下,可以给 OrangePi AIpro 加多一个摄像头模组,然后通过每0.5秒拍摄一张图片的方式,调用Yolov5的模型,进行实时的车牌号识别,这样咱们就很方便的完成了一个高效的车牌识别摄像头😋。
香橙派AIpro开发板在文字识别项目中展现出了卓越的性能和易用性,它不仅为开发者提供了强大的硬件支持,还通过丰富的社区资源和完善的软件生态,降低了开发门槛,提升了开发效率。对于希望在AI领域进行探索和应用的开发者来说,香橙派AIpro无疑是一个值得推荐的选择。我相信,在未来的项目中,它将继续发挥重要作用,助力我实现更多创新想法。